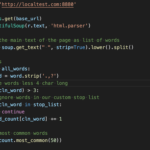
Today’s quick python script is all about finding what are the top repeated words within a webpage. The idea for this came to me when I was thinking about processing sites I found on a Google Search and possibly generating a database of common words for each site to help me find useful documents related
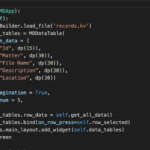
I continually search for methods to finding the row a user selects in a KivyMD MDDataTable. There are not as many useful results in my Google searches to assist in finding a solution. Most of the results only show printing the incoming variable objects in the call back function. The on_press action for the table
Let me start that I am not an authority on regular expressions (regex), and I am fairly new to programming in Python. I was taxed with reviewing some web server logs for a software product I support that uses Apache Tomcat. This is an example of how I tried to solve this issue of identifying
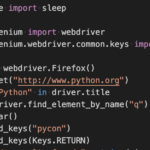
Selenium can be fun to play with, but really best used for website testing. I needed to see if I could quickly setup and test how Selenium works, so that I can prepare some tests for the web client of the software package I work with at the office. And I was really impressed on
How often do you find a news article link somewhere that looks really interesting to read, but the article is packed full of ads and distractions you have a difficult time discerning where the news article text is located on the page? Some of these ads can take over your screen or block your view.
As of May 2020, I am using Python 3.8.2. The following article is configured with the version in mind that I am using. I believe the setup that follows works back as far as Python 3.6 (but I am unsure). See Python.org for the latest documentation. The goal of this article is not to be