Method to parse a Tomcat access log file with python regex
Let me start that I am not an authority on regular expressions (regex), and I am fairly new to programming in Python. I was taxed with reviewing some web server logs for a software product I support that uses Apache Tomcat. This is an example of how I tried to solve this issue of identifying the data in the Tomcat localhost_access log files.
As of today, I have only gotten to the point of passing a single file in the current directory of the script. I parse the file line by line which returns a python dictionary of all the line items in the file. The next stage to complete at a later time is to process the full directory of access log files and generate a report on the data. I am stalled at this point until I get a clear definition of what the report should look like, the first goal was to prove proof of concept that I could at least parse the data.
The sample data point is in the format similar to the following, where there is one entry like this per line in the file. All line entries have the same format.
128.14.134.170 - - [15/Mar/2020:00:15:29 -0400] "GET / HTTP/1.1" 200 11497The first portion is the IP address of the visitor, then is a date, followed by the type of request and requested url and the HTTP format. Next is the HTTP response code and the response in bytes. See the Apache Tomcat 8.5 Access Logging documentation for further details
To process each line in the log file, I created a complex regex to split up the parts and save them into individual variables. Here is the regex pattern I used:
(^\d+\.\d+\.\d+\.\d+).*\[(.*)\].*\"(.*)\"\s(\d+)\s(\d+)First note the groupings where the parenthesis are. I am unsure about other programming languages, but for python using the re module the returned result of the search() function contains a match group where the first item in the match is the full matched string, and the remaining items in group() are the individual groupings as signified by the parenthesis.
So in the example above, group(1) has the following:
(^\d+\.\d+\.\d+\.\d+)which will look for four sets of digits separated by periods at the beginning of the line. The ‘^’ signifies the beginning of the line. The ‘\d+’ says to match one or more digits. And since the period is a special character that means to match any number of items, if we want to search for a period we need to escape it with the backslash like so ‘\.’
For group(2) I used the following to get the date:
\[(.*)\]Notice that i kept the square brackets outside of the grouping, as i only wanted the date portion and not to include the brackets. Since brackets are a special character in regex, those needed to be escaped. In the parenthesis I used ‘.*’ which means to look for any character zero or more times
For group(3), I used the following to get the HTTP request information:
\"(.*)\"This is very similar to the date grouping above, but noticed that i escaped the special character double quotes and left them outside of the grouping so as to not be included in the match result (note, in my earlier testing I had them inside the parenthesis and my match included quotes which I did not need).
The last two groupings were very simple and just looking for a set of numbers separated by a space.
Put these all together and you get something akin to the following:
(128.14.134.170) - - [(15/Mar/2020:00:15:29 -0400)] "(GET / HTTP/1.1)" (200) (11497)
ie.)
(group one) - - [(group two)] "(group three)" (group four) (group five)Here is the python code snippet:
#!/usr/local/bin/python3
import re
access_data = []
def parse_access_log_line(line):
parseddata = re.search('(^\d+\.\d+\.\d+\.\d+).*\[(.*)\].*\"(.*)\"\s(\d+)\s(\d+)', line)
result = {
'ipaddress': parseddata.group(1),
'date': parseddata.group(2),
'request': parseddata.group(3),
'responsecode': parseddata.group(4),
'responsebytes': parseddata.group(5),
}
return result
def process_localhost_access_file(access_file):
with open(access_file) as file:
for line in file:
access_data.append(parse_access_log_line(line))
print(access_data)
process_localhost_access_file('./localhost_access_log.2020-03-15.txt')To walk through the script, we first import the ‘re’ module from the python Standard Library. Then created two functions, the first will parse a line of data and return a dictionary result. The second function will eventually return a list of dictionary data items, but for now just prints out the full list to stdout.
In the ‘parse_access_log_line(line)’ function, we pass in a single line from the file and setup the regular expression search. The parseddata variable will hold the match data. We call the group() method on the match data passing in which item number in the grouping list and assign each to the proper dictionary item. The match list group() for the sample above would look like the following:
['128.14.134.170 - - [15/Mar/2020:00:15:29 -0400] "GET / HTTP/1.1" 200 11497', '128.14.134.170', '15/Mar/2020:00:15:29 -0400', 'GET / HTTP/1.1', '200', '11497']
ie.)
['full match as group(0)', 'group(1)', 'group(2)', 'group(3)', 'group(4)', 'group(5)']The function ‘process_localhost_access_file(access_file)’ is a simple function that opens the log file and iterates over each line and appending the result of the call to parse the line to an accumulation list of ‘access_data’. As I said, for now this data is just printed out.
And to start the process we call the process local access file function. I really should have set that function to return a cumulative result that will later be called by another function that has to walk the log directory, but this was just a proof of concept. I hope to expand upon this and rewrite this article. But for now, this is just a handy place for me to remember how I did this as I will likely be side tracked to work on another rush project. Ah, the beauty of being the only support person in the building, someone is always asking for my assistance before I can finish one project.
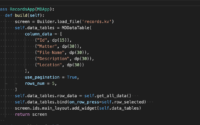
Finding the row a user selects in a KivyMD MDDataTable
How I read the News without ads (WordPress based News Sites)